

A Timeline of AI Progress
Thinking about what matters and what doesn't in AI.

I originally put this slide together for the September 2025 edition of BRXND. It is a timeline of what I would consider the major milestones in AI over the last five years. The orange ones are the things I think are worth paying attention to. It was designed to scale as best I could with my limited Figma skills.
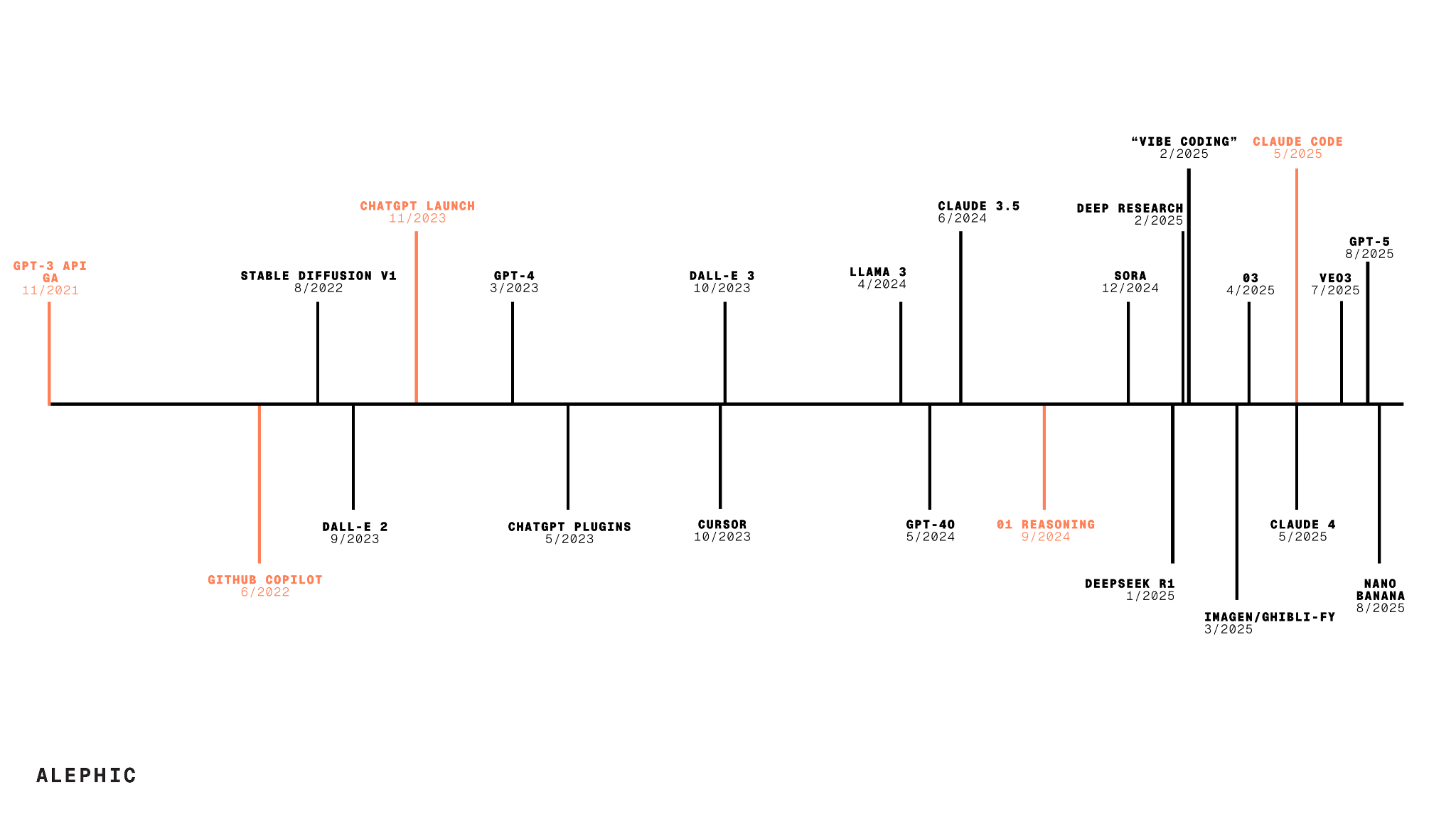
There are two things that should stand out:
There are fewer moments than you would assume over the last five years. That’s because I purposely left out every small model update and focused on the bigger events.
There are only five highlighted moments. Despite arguments to the contrary and the never-ending parade of model releases, I genuinely believe AI has undergone only a few major changes over the last five years.
My five moments with their defenses:
November, 2021—GPT-3 API goes GA: This one is easy for me. We could draw the line in the sand almost anywhere after the Attention is All You Need paper, but to me, putting these things in the general public’s hands (albeit in API form) is a good demarcation point. There are still the “I’ve been doing AI for years” people complaining that ML is AI, but what’s possible before and after the GPT-3 API is very different.
June, 2022—GitHub Copilot goes GA: it’s easy to take for granted now, particularly with the conversations happening around uptime and GitHub, and the eventual direction Microsoft took the Copilot brand, but that initial autocomplete product in VS Code felt like magic and was the first real productization of AI.
November, 2022—ChatGPT Launch: This is the easiest one, and everyone likes to talk about it. Lots of us were building chatbots on our own, and this felt like such an obvious next step. Funny enough, this also immediately shifted Copilot use because while autocomplete was cool, chat turned out to be the killer app for coding (a fact Copilot seemed to miss and Cursor eventually ate their lunch on).
September, 2024–o1 Reasoning: The Google chain of thought paper came out in early 2022 and showed that adding reasoning to prompts significantly improved the models’ ability to reason, but it took two and a half years for OpenAI to build it into a model. o1 was big and slow, but set the groundwork for everything that followed. Though we didn’t realize it at the time, the real magic of these reasoning models wasn’t just that they were much better thought partners. Function calling was introduced to models in June 2023, but before reasoning models, it was incredibly inconsistent—better for demos than for real work. Reasoning changed that, allowing the model to plan its function calls before executing them.
May, 2025–Claude Code: finally, we have Claude Code, which celebrates its first birthday this month. If o1 made function calling work, Claude Code wrapped it in an agent loop: inspect the repo, decide what to do next, call a tool, read the result, and keep going. The tools themselves were simple UNIX commands, deeply covered in the pre-training data thanks to half a century of UNIX documentation. While lots of people believe that Opus 4.7 unlocked the harness, I think the causality goes the other way.
Despite how easy (and fun) it can be to get lost in each new model release or tool update, the reality is that most of it is just gradual improvement. That’s not to say it’s not tremendously valuable—GPT 4o unlocked ChatGPT in new ways—but those weren’t step changes in what is possible, they were the kind of slow progress that we always find hard to measure.
To that end, I have a few observations and thoughts from this list.
First off, each of these step changes is still very much building on the previous one. ChatGPT doesn’t happen without GPT-3, just like Claude Code doesn’t happen without o3. Reasoning models themselves are obviously evolved from prompting techniques. That can make AI progress feel Darwinian, but W. Brian Arthur’s point in The Nature of Technology is more specific: technologies evolve by combination. New things are assembled out of existing components and the phenomena they harness; sometimes better variations win, and sometimes a new principle arrives that makes the old family tree less useful. The jet engine isn’t just a better propeller. His focus is mostly hardware, not software, but it still makes me wonder if we should expect more radical changes, or maybe we’re just settled into this architecture, and that’s how we should expect innovation to happen. Here’s how Anthropic co-founder Jack Clark put it recently:
As a field, AI moves forward on the basis of doing ever larger experiments that utilize more and more inputs (e.g, data and compute). Every so often, humans come up with some paradigm-shifting idea which can make it dramatically more resource efficient to do things - a good example here is the transformer architecture and another is the idea of mixture-of-expert models. But mostly the field of AI moves forward through humans methodically going through some loop of taking a well performing system, scaling up some aspect of it (e.g, the amount of data and compute it is trained on), seeing what breaks when you scale it up, figuring out the engineering fix to allow it to scale, then scaling it again.
Another interesting observation is that image and video models are mostly missing on this timeline. I don’t quite know what to make of these models, and that’s part of the reason I’m writing this post. Every time a new step change in capability comes along (like Nano Banana or, more recently, GPT Image 2.0), we see people say everything is going to change, and then mostly not a lot changes. As practitioners of AI and marketing, we are making good use of the current crop of models with a variety of customers for a variety of use cases, but it feels like the Copilot/ChatGPT/Claude Code moment just hasn’t arrived yet. Obviously, diffusion as an approach is amazing and probably deserves a place on the list, but the leaps feel much more gradual and make it hard to draw conclusions. With all that said, the release of GPT Image in March 2025 caused an explosion of usage in ChatGPT.
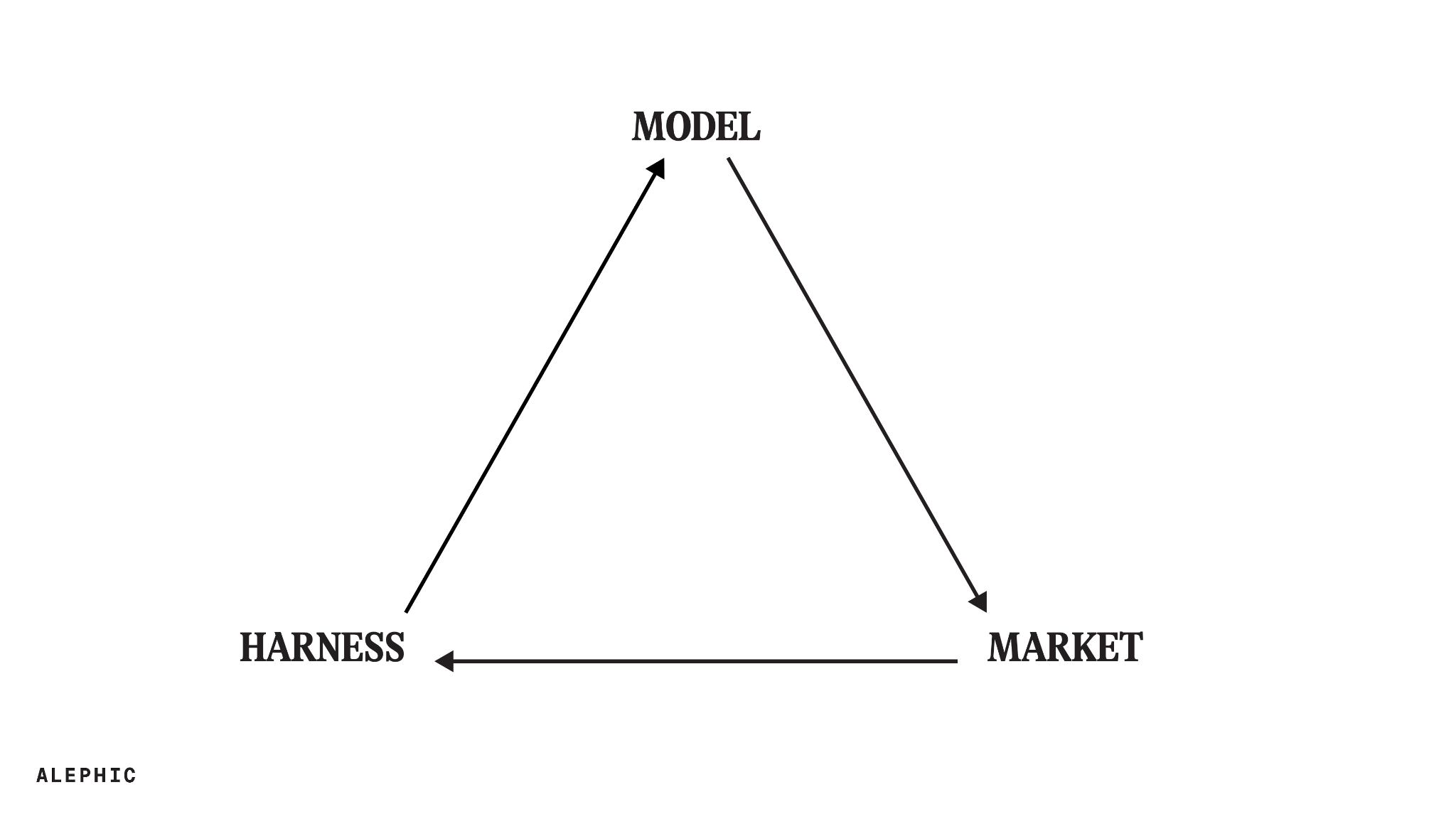
To that point, maybe the most fundamental takeaway from the timeline is that the real leaps in usage come from a kind of weird alchemy between model, market, and harness. The model has to be good enough to do the job, the harness has to expose that capability in a form people can actually use, and the market has to be in the right place to see the full value. Each one of these episodes caused a step change in token demand. Anthropic’s own annualized run-rate numbers make the point: the company went from approximately $9 billion at the end of 2025 to more than $30 billion by early April 2026.
Sholto Douglas, an Anthropic researcher focused on scaling reinforcement learning, made a version of this point on a 2025 episode of the Dwarkesh Podcast: Cursor had been around for a while, but with Claude 3.5 Sonnet, “the model was finally good enough that the vision they had of how people would program, hit.”
That’s why the causation is so hard to pin down. Lots of people are sure that Claude Code exploded in December because of the release of Opus 4.7. As a relatively early adopter of CC, I’m a lot more skeptical. Many of us were getting tremendous value out of the harness in June and July. I think it’s much more likely that the real thing that happened in December is that a bunch of people just had more time to give the tool an honest go, and when they did, they were blown away.
Claude Code creator Boris Cherny calls this “product overhang.” The model’s capabilities often remain untapped until the right code comes along to unlock them. What I think this timeline adds is that there is a market overhang, too. The model can be good enough, and the harness can exist, but the market also has to be ready to notice, care, and change behavior. The highlighted moments are when model, harness, and market meet.
So what comes next? I don’t know. The three things I keep coming back to are reliable computer use, secure mobile agentic capability, and real document collaboration. I don’t know if any of them are the thing, but they all feel like potential unlocks for the next step change in token demand.